2022 年 8 月にオープンソースとして無償公開され話題になった画像生成 AI 「Stable Diffusion」 ですが、面白そうなので実際に動かして遊んでみようということで、Google Colaboratory (以下、Google Colab) で稼働させてみました。
Stable Diffusion を Google Colab 上で稼働させる方法についてはすでに色々なところで紹介されているので細かくは書きませんが、それら情報のおかげで簡単に稼働させることができましたので備忘録がてらに書いておきます。
Stable Diffusion とは?
Stable Diffusion is a text-to-image latent diffusion model created by the researchers and engineers from CompVis, Stability AI and LAION. It is trained on 512x512 images from a subset of the LAION-5B database. LAION-5B is the largest, freely accessible multi-modal dataset that currently exists.
「Stable Diffusion は、CompVis、Stability AI、LAION によって開発された、テキストから画像を生成する Diffusion Model (拡散モデル) です。LAION-5B (LAION が提供する画像とテキストのペアを収めた AI 用トレーニングデータベース) から 512 × 512 サイズの画像を使用して学習が行われました。」
ということで、Diffusion Model については私はあまり詳しくないのですが、下記の記事で解説されていますので興味のある方は読んでみると面白いと思います。
あと、「512 × 512 サイズの画像を使用して学習している」 というのもポイントのようで、画像生成の際にアスペクト比が 1:1 以外の画像も指定すれば生成できますが、学習の元がアスペクト比が 1:1 の画像なので、なるべくそれと同じ正方形の画像を生成した方が精度は高くなるみたいですね。
参考にした記事
それでは実際に動かしてみるところまで進めましょう。
基本的なことは下記の記事、及び Diffusers の GitHub リポジトリにある Readme に全部書かれていますので、それを参考にしました。
- Google Colab で はじめる Stable Diffusion v1.4 - npaka - note
- Stable Diffusion with 🧨 Diffusers
- huggingface/diffusers: 🧨 Diffusers: State-of-the-art diffusion models for image and audio generation in PyTorch - GitHub
大まかな手順
まず最初に、Hugging Face のアカウントを持っていない場合は取得してログインします。
そしたら下記、「Stable Diffusion v1-4 Model Card」 のページにアクセスし、「You need to share your contact information to access this model.」 部分のライセンスなどを確認して 「Access Repository」 ボタンを押します。
Hugging Face にログインした状態で自分のアカウントの設定画面に行くと、「Access Tokens」 という項目がありますので、わかりやすい名前を付けた上でトークンを発行します。
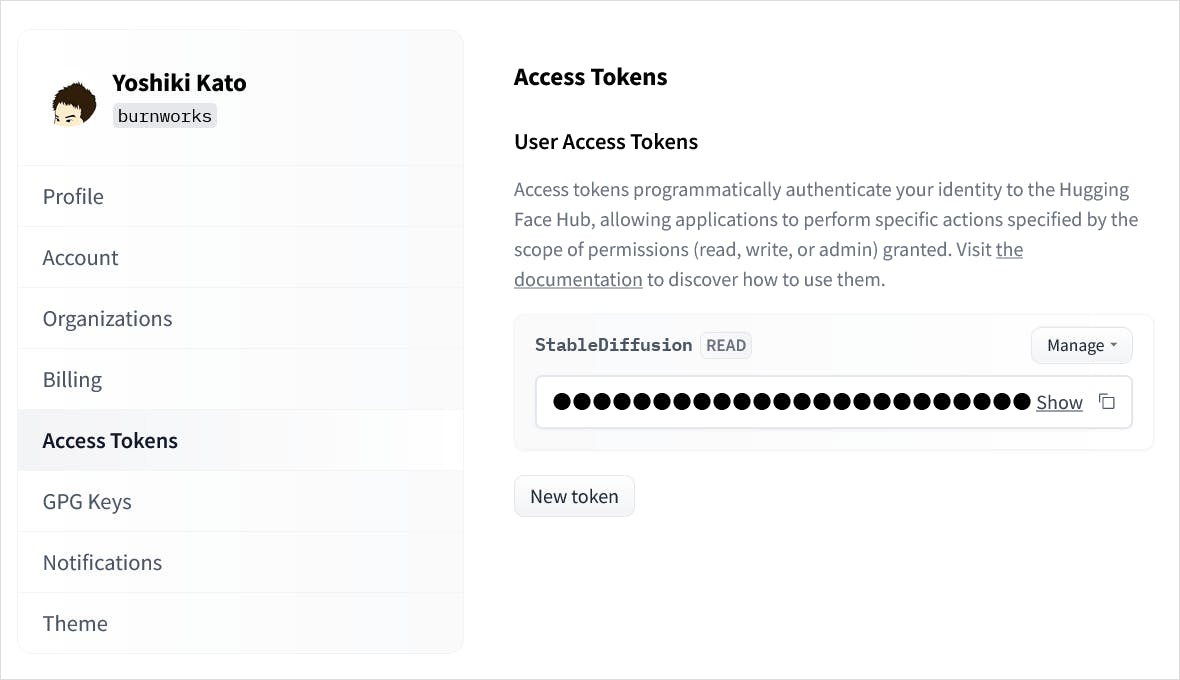
これで下準備は完了。
次に Google Colab にアクセスしましょう(Google アカウントは持っている前提)。
新しいノートブックを作成しますが、その際に 「編集」 → 「ノートブックの設定」 と進んで、「ハードウェア アクセラレータ」 の選択を 「GPU」 にするのを忘れずに。
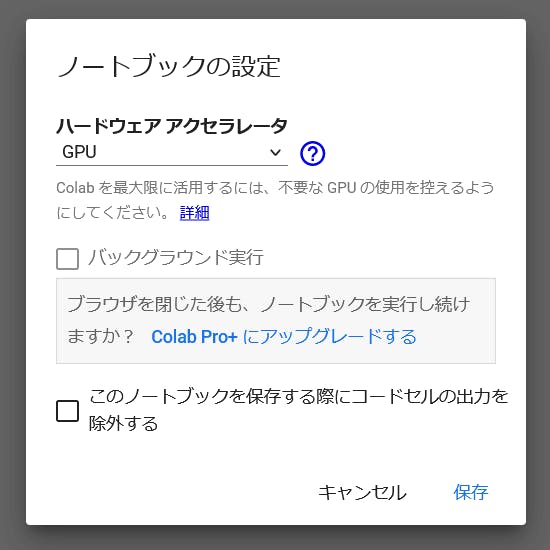
あとは、下記のように順次コードを実行していきます。
まずは Stable Diffusion をはじめ、必要なライブラリをインストール。
!pip install diffusers==0.2.4 transformers scipy ftfy次に先ほど取得したアクセストークンをセット。
YOUR_TOKEN="ここに取得した Token を入力"パイプラインを準備します。
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", use_auth_token=YOUR_TOKEN)
pipe.to("cuda")あと、私の場合は出力した画像を自分の Google Drive に保存したかったので、まず、ノートブックの 「ファイル」 タブにある 「ドライブをマウント」 ボタンを押して、Google Drive と関連付けましょう。
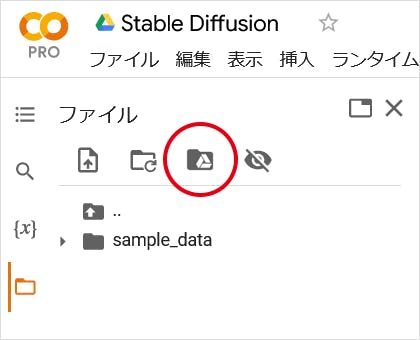
マウントが終わると、Google Drive に 「Colab Notebooks」 というフォルダができると思います。私はさらにこの下に 「StableDiffusion」 というフォルダを作ったので、下記のコードを実行して保存先を指定します。
import os
os.chdir("/content/drive/MyDrive/Colab Notebooks/StableDiffusion")あと、書き出す際のファイル名の決定などを自動化したかったので下記のライブラリを読み込むようにして、
import datetime
import pytz
import reいよいよ、画像を生成します。
prompt = "ここに呪文"
now = datetime.datetime.now(pytz.timezone('Asia/Tokyo'))
date = now.strftime('%Y-%m-%d-%H-%M-%S')
filename = re.sub(r'[\\/:*?"<>|,]+', '', prompt).replace(' ','_')
outputfile = filename + '_' + date + '.png'
image = pipe(prompt, num_inference_steps=50)["sample"][0]
image.save(outputfile)AI に画像を発注する文言はここに入力します。プロンプトのコツについては後述します。
prompt = "ここに呪文"下記の部分は出力ファイル名を自動で設定するためのもの。まず、datetime と pytz を使用して、ローカルタイムを取得し、そこからファイル名に付ける日時を生成しておきます。
now = datetime.datetime.now(pytz.timezone('Asia/Tokyo'))
date = now.strftime('%Y-%m-%d-%H-%M-%S')入力したプロンプトをそのままファイル名に使っておけばあとで忘れることもないので便利なんですが、プロンプトにファイル名で使えない文字列が入っていたときに面倒くさいのでその辺を除去。「,」はファイル名に入っていても問題ないんですが、プロンプト内で結構使うし、邪魔なので削除しちゃいます。
filename = re.sub(r'[\\/:*?"<>|,]+', '', prompt).replace(' ','_')で、上記で作ったファイル名と、先に生成しておいた日時を組み合わせてファイル名を決定します。
outputfile = filename + '_' + date + '.png'実際に画像を生成して保存します。num_inference_steps=50 は初期値が 50 なのでこの例だとわざわざ付ける必要はないんですが、Colab Pro とか有料版を使っている場合はここの数値を上げると画像生成のステップ数が上がってより詳細になるらしいです。
ただ、その分時間もリソースも消費します。試してみた限り、初期値でも十分綺麗な画像が生成されると感じました。
image = pipe(prompt, num_inference_steps=50)["sample"][0]
image.save(outputfile)ということで、プロンプトを編集しつつ画像を生成すると、色々と画像が出力されて面白いです。
プロンプトを考える
Stable Diffusion を Google Colab で実行するだけならここまで読んでいただければわかるとおり簡単ですしすぐにできると思いますが、問題はプロンプトをどうするかですね。
人間同士でも頭の中にアルイメージを正確に伝えるのは超難しいわけですが、AI 相手にそれをやらないといけない。しかも人間同士ならわからない点は質問したりしてイメージをすりあわせることができますが、AI 相手の場合は出てきた出力 (画像) をみて、「あぁ伝わってねぇ......」 とか 「こういう風に発注してみたらどうだ」 みたいな試行錯誤をする必要があります。
で、さすがだなというところで下記の記事は非常に参考になりました。
とりあえず、難易度低めと思われる風景画、というか風景写真を生成してみようということでやってみたのが下記です。
生成した画像サンプル

プロンプトは簡単で、
Beautiful concept art of landscape taken by Caanon EOS 5D Mark4 and SIGMA Art Lens 35mm F1.4 DG HSM, F1.4, ISO 200 Shutter Speed 2000
みたいな感じ。
上で紹介した記事の 「困ったときはカメラ設定書いとけ」 をやってみたら本当に良い感じのが出てきてビビった。あと、最後に 「blue」 とか好みの色味みたいのを足してみたりすると、少し違うのが出てきたりで面白いです。
ちなみにこの記事の OGP 画像に設定している画像も Stable Diffusion さんに生成していただいたものですが、こちらの発注としては
Beautiful concept art of Artificial Intelligence by TETSUYA ISHIDA
ということで、石田徹也氏テイストで 「人工知能」 をお題に書いて欲しかったんですけども、もしかすると石田徹也氏を認識していない気がします。私、氏の作品好きなんですけどね。




